八股文
2025-04-10
栈和堆在存储内存中的区别:
栈的内存都是有系统自动分配,同时在进程结束之后会自动将分配的内存销毁。但是堆的内存则是由操作员自行分配,同时需要自行释放内存。栈申请到的内存都是线性的,但是堆则是动态分配的,在内存的管理上,因为栈是线性的,采用后进先出的规则,所以只需要移动指针就行,但是堆则是需要搜索链表,这样会存在"内存碎片"的情况。在需要小内存的情况下,使用栈是更高效的选择,但是在大内存的情况下,因为栈的大小是固定的,可能会导致栈的溢出,所以用堆会更好。
堆(数据结构)
堆都是完全二叉树(除最底下一层之外,其它层全满,在最底下一层,从左到右不能有空的)
大根堆:所有的父节点都大于子节点。小根堆则是所有的父节点都小于子节点。
通过对二叉树的层序遍历,对每一个节点进行编号,建立相关的一维数组,并将节点的数字依次填入一位数组,并用数组下标表示二叉树节点的编号,而数字与下标编号一一对应。
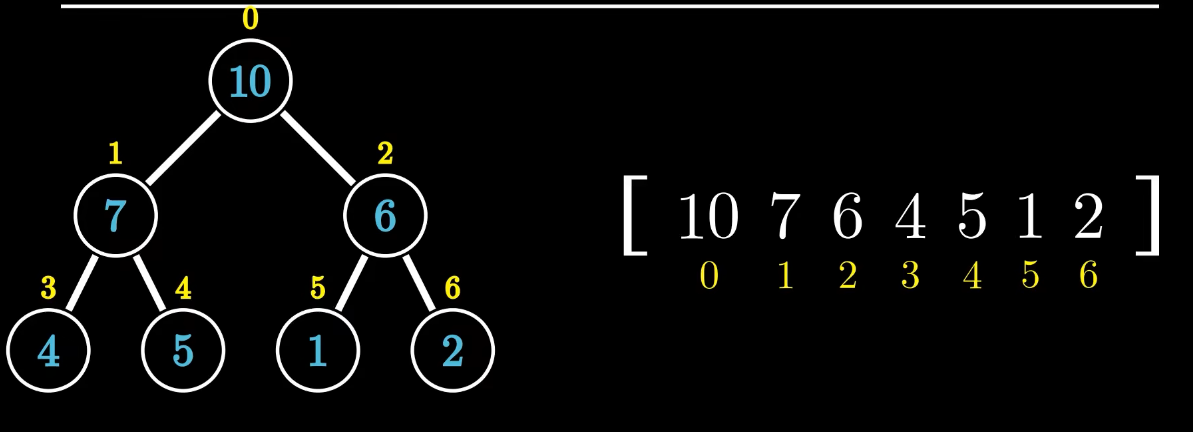
同时可以看出 父节点i,左子节点是2i+1,右子节点是2i+2。
下虑:只有树的根节点不满足堆序性的要求,所以通过将根节点不断的与子节点进行交换,直到能够满足堆序性的要求。
上虑:就是通过将子节点不断的上移来满足堆序性的要求。
http的优点
1,传输安全可靠。底层逻辑是通过TCP协议来进行传输,TCP协议会通过“三次握手”来确保传输路径的通畅,同时还会将大的数据分割成小的数据段来进行传输。同时还采用了IP协议来确保目标IP的正确,实现精准的传输。
2,灵活。http协议支持多种类型资源的传输,除了文本之外,还有视频,图片,音频之类的。
3,快速。通过请求报文和响应报文来进行传输,并响应报文中附带所请求的传输资源就可以。同时还有多种请求方法,例如get,post等。针对不同的请求类型来选择不同的请求方法。
4,无状态性。服务器不会记录上一次客户端的请求,这样就减少了服务器的资源占用,同时也避免了一次请求失败影响全局的情况。
Cookie和Session的运作方式
Cookie:客户端第一次访问服务器,服务器会在响应报文带上一个Cookie传入客户端,并且这个Cookie就会保存在客户端,短时间内客户端第二次访问服务器的时候,服务器的请求头上就会带上这个Cookie,这样实现了状态信息的存储。
Session:主要是客户端拥有一个Cookie来存储SessionID,只要在请求头上携带这个SessionID传给服务器,经由服务器来验证这个SessionID来实现状态信息的存储。如果客户端被禁用Cookie,则会采用URL重写的技术,在URL中加入sid=xxx实现SessionID的传输。
Cookie和Session的区别
1,存储资源类型的不同
Cookie只能存储ASC码的字符串,如果想使用其他类型的资源,需要进行编译。同时也是不支持JAVA的类对象的。但是Session则是什么类型的资源都可以存储。
2,隐私保护上
因为Cookie是存储在客户端上的,同时在资源请求的过程中也会有它,所以会出现被人恶意抓包然后篡改的情况,这会导致使用者的隐私泄露。但是Session是存储在服务器上的,就不会出现这个情况。
3,有效期上
Cookie可以通过更改有效期,把数字改的很大,这样就可以是实现Cookie的长期存储,但是Session不可以,Session一旦关闭了阅读器,那么Session会话就会失效,同时Session过多的存储在服务器上,可能会导致服务器的“内存溢出”。
4,服务器压力上
Cookie是存储在客户端的,对于服务器的压力会比较小,但是Session是存储在服务器上的,如果网站的使用量过大,这样会导致服务器的压力过大。
状态码
500:请求未完成,服务器遇到不可预知的情况。
501:请求未完成,服务器不支持所请求功能。
502:请求未完成,服务器从上游服务器收到一个无效的响应。
503:请求未完成,服务器临时过载或宕机。
504:网关超时。
505:服务器不支持请求中指明的HTTP协议版本。
400:服务器未能理解请求。
401:被请求的页面需要用户名和密码。
402:此代码尚无法使用。
403:对被请求页面的访问被禁止。
404:服务器无法找到被请求界面。
get
get也是可以进行数据传输的,主要是通过URL的请求附带参数来进行数据的传输,但是受限于URL的长度,所以并不能传输过多的资源。同时get因为URL是可见的,所以并不是非常安全。同时get传输是只支持ASC码的字符的。
TCP连接
TCP通过4个值来识别:源IP地址,源端口号,目的IP地址,目的端口号
代理
代理位于客户端和服务器之间,接收所有客户端的HTTP请求,并将这些请求转发给服务器(可能会对请求进行修改之后转发)
正向代理:是一个中介,代理请求者的网络内部,访问网络外部。
反向代理:请求到达服务器,转发到内部其他的服务器。
缓存
web缓存或代理缓存是一种特殊的HTTP代理服务器,可以将经过代理传送的常用文档复制保存起来。
客户端从附近的缓存下载文档会比从远程web服务器下载快得多,HTTP定义了很多新的功能,使得缓存更加高效,并规范了文档的新鲜度和缓存内容的隐私性。
缓存减少了冗余的数据传输,节省了你的网络费用。
缓存缓解率网络瓶颈的问题,不需要更多的宽带就可以更快的加载界面。
缓存降低了对原始服务器的要求,服务器要求更快的响应,避免过载的出现。
缓存降低了距离时延,因为从较远的地方加载界面会稍微慢一点。
处理步骤:
1,接受HTTP的报文请求。
2,对报文进行解析,
3,判断缓存中是否有相关资源,
4,判断资源是否是新的,
5,创建响应报文
系统性能优化
1,架构,业务和程序的优化最有效
优化系统架构:
集群,分布式计算,负载均衡,多台应用,多台DB,多台缓存,CDN
业务逻辑的优化:
减少需要大量同一时间访问的业务,均摊在不同的时间执行。
程序优化:
找到程序中最耗时的部分,进行算法优化,缓存优化,根据业务情况将同步请求转化成异步请求。
2,数据库优化:
建立和优化引索,分库分表,读写分离,优化数据库的函数,减少表空间的占用,减少重复数据存储,减少数据库的函数,存储过程,触发器所有内部计算功能,优化连接数。
3,中间件优化:
连接数,缓存,内容大小。
4,JVM虚拟机参数优化
HTML5的新特性
增加了很多新的语义标签:header footer article section aside main ,可以通过标签更好的描述网页的结构,提高代码的可读性。
增加了很多的表单类型:date,time,range。表单验证机制,输入框的提示内容,require强制填写字段。
多媒体支持:视频,音频的播放,暂停。
canvas:制作一些动态的图标。
web storage:可以在客户端存储一些数据资源。
获取用户地址信息。
构造函数
实例化对象之后,在堆区会分配空间给这个对象,这个时候this指向这个实例化的对象。如果出现调用函数的情况,谁调用就指向谁。
面向对象里通过new来生成实例对象的函数。
原型和原型链
原型的目的是让具有相同功能的函数能够够共用一个内存。相似的对象可以调用共同的方法。通过对构造函数的.prototype来进行调用。
原型链,先在对象中寻找,之后去创建函数的构造函数.protoytpe去找,再去object.__proto__去找。
http协议的层级
OSI的七层结构体系:物理层,链路层,网际层,传输层,会话层,表示层,应用程。
TCP/IP的四层结构体系:链路层,网际层,传输层,应用层。
五层体系结构:物理层,链路层,网际层,传输层,应用层。
其中应用层 HTTP协议,DNS协议。传输层 TCP协议,UDP协议。 网际层:IP协议。
路由器在用tcp/ip进行分组转发的时候最高只用到网际层而没有运用运输层。
IP协议
任何一个参与到网络的设备都需要被分配一个IP地址,同时在实际传输的过程中,IP地址会被转化成网卡的物理地址(MAC地址)来完成数据的通信。
TCP协议
TCP会把大的数据分割成小的报文段,并把数据传输给对方。
“三次握手”
第一次,客户端发送带有SYN标识的数据发送给服务端,以此证明客户端可以正常发送数据。
第二次,服务端发送带有SYN/ACK标识的数据发送给客户端,以此证明服务端可以正常的收发数据。
第三次,客户端将数据去掉SYN,只含有ACK标识的数据发送给服务端,以此证明客户端可以正常的接收数据。
DNS协议
DNS负责提供域名到IP地址的解析服务。
数据发送的大致流程
客户端首先通过DNS服务器来将域名进行解析,获得目标服务器的IP地址。之后发送HTTP请求报文,通过TCP协议将请求报文分割成小的数据段,并通过IP协议进行传输,在目标服务器通过TCP协议来重组请求报文并进行响应处理,最后发送响应报文。
HTTP协议的安全性
SSL:安全套接层。TSL:安全传输层协议。同时通过HTTP+SSL=HTTPS 来建立安全通路。
加密报文体:
针对http发送的报文体进行加密,但是需要客户端和服务端都支持加密,此举会提升复杂度。
一般般都是采用两种结合的形式来提升数据传输的安全性。
超文本
不仅可以传输文本类型,同时还可以传输其他类型的资源,例如音频,视频之类的。
URI和URL
URI:统一资源标识符。
URL:统一资源定位符(网址)。
“https://www.sniper.com:80/page/helloworld.html?gid=123&name=Alen#ch1”
在上述的网址中:
“https”:表示协议名(http,ftp,telnet)
“www.sniper.com”:表示服务器地址(域名/IP地址)
“80”:该服务器的端口号。
“/page/helloworld.html”:资源路径(类似于文件和目录的结构,表示这个资源在该服务器的位置)
“gid=123&name=Alen”:请求的附带参数(多个请求参数用&隔开,同时类型都是key=value结构的字符串)
“ch1”:片段标识(锚点,标识文档或资源中的某个具体的位置)
报文
http协议的报文分成两种,请求报文和响应报文。
如果想访问“https://www.sniper.com/page/helloworld.html”
请求报文:
GET /page/helloworld.html HTTP/1.1
Host: www.sniper.com
connection:keep-alive
content-Type:application/x-www-form-urlencoded
content-Length:0
{内容实体}
首先第一行表示请求行,其中“GET”是请求方法,“/page/helloworld.html”是资源位置URL,“HTTP/1.1”表示http协议版本。
之后的4行是报文的请求头,其中"Host”表示该服务器的IP地址。“connection”表示连接方式。“content-type”表示请求数据的类型。“content-length”表示报文体的长度。
之后需要空一行,
之后就是内容实体。
响应报文:
HTTP/1.1 200 OK
Date:sun,28,Jul,2021 06:50:15 GMT
content-Type:text/html
content-Length:1234
<html>......</html>
其中第一行是状态行,“HTTP/1.1”是协议版本,“200”是状态码,“ok”表示原因。
之后三行是响应头,“Date”是时间戳。
然后空一行
之后就是返回的资源。
请求方法
Get:获取资源,通常并不带有报文体的内容。
Post:传输实体,报文体带有所需要的资源。
Put:向服务器传输资源。
Delete:向服务器删除资源。
Head:与Get相似,但是不要求返回报文体。
Option:查询服务器支持哪些请求方法。
TRACE:让服务器将之前的请求通信传回给客户端。
Connect:建立传输通道。
状态码
1xx(信息性状态码)请求正在处理。
2xx(成功状态码)请求成功处理完毕。200:成功处理。204,206:返回所需资源的一部分。
3xx(重定向状态码)需要进行附加操作以完成请求处理。301:表示该请求资源已经永久的转移到新的URL,需要跳转至新的URL来获取该资源。
302:表示请求资源暂时转移到新的URL,过一会还是可以正常访问的。
4xx(客户端错误状态码)403:客户端没有权限请求该资源。404:服务器没有客户端请求的资源。
5xx(服务器错误状态码)500:服务器内部出错。
Cookie
Cooike是由服务端下发给客户端并有客户端来存储的身份信息,在后续的请求时,带着Cookie。并不安全,可以随意伪造,服务端也无法判断Cookie的真伪。
Session
客户端与服务器建立一个短暂的会话,Session的信息被存储在服务器端,同时客户端通过Cookie来获得Session的ID。Session的ID难以被预测,并且是有有效时间的,Session在服务器端一般般是非持久化的存储,服务器端负荷比较大,同时不支持多台服务器之间的共享传输。
Token
Token(令牌)是服务器进行加密的一串字符串,再次请求时,服务器针对Token进行解密,验证访问者的身份。同时Token一般般会存储在客户端中,相比于Cookie更安全,同时也支持多台服务器之间的共享。
HTTP协议的特点
最主要还是灵活和可拓展。
分组交换的优缺点和http协议的关系
优缺点:
高效 动态分配传输带宽,对通信链路是逐段占用。
灵活 以分组为传送单位和查找路由。
迅速 不必先建立就能像其他主机发送分组。
可靠 保证可靠性的网络协议;分布式的路由选择协议使网络有很好的生存性。
分组在各个节点存储转发时需要排队,这就会造成一定的时延。
分组必须携带首部,也造成了一定的开销。
分组交换是http协议的底层核心机制,http依赖于tcp/ip协议,ip协议的分组交换机制是http数据传输的基础。
时延
发送时延:数据从一个节点全部发送出去的时延。
传播时延:数据在链路上传播的时延。
处理时延:节点接收数据并进习惯处理的时延。
排队时延:数据在节点进行排队所需要的时延。
总实验=发送时延+传播时延+处理时延+排队时延。
http协议中层级的流程
应用进程程序先传输数据带应用层,加上应用层首部,成为应用程pdu,应用层pdu再传送到运输层,加上运输层首部,成为运输层报文,运输层报文在传送到网际层,加上网际层报文,成为网际层报文,运输层报文再传送到网际层,加上网际层首部,组成ip数据报(分组),ip数据报再传送到链路层,加上链路层首部和尾部,成为数据链路层帧,数据链路层帧再传送到物理层,把比特流传送到物理媒体,利用电信号和光信号在物理媒体中传输。
http缓存
如果存在有很多的相同资源的请求,我们就可以将这些存储在客户端的响应副本返回给用户。
http缓存分为两种缓存,一种是强制缓存,另一种是协商缓存。这俩的区别在于:在缓存命中的时候,浏览器会询问服务器是否对资源有更新,如果有的话就用最新的资源,没有的话就采用缓存资源。
强制缓存
强制缓存方式返回,通过对于判断设计的时间是否过期来进行判断。“cache-control:max-age:5”:含义就是当前服务器时间经过了5秒内,就走缓存,如果超时就还是走正常的请求。
no-store:不采用强制缓存。no-cache:来强制执行协商缓存。cache-control中设置public,表示相应资源可以被浏览器缓存,又可以被代理服务器缓存。如果设置private的话,就只能被浏览器缓存,不能被代理服务器缓存。例如图片这种不会被多次改变的资源就可以用public。
s-maxgae和max-age是相似的,都是控制缓存的过期时间,但是不同的在于s-maxage是针对于代理服务器的缓存,同时也需要将cache-control是要用public来设置的。
协商缓存
协商缓存是在使用本地缓存之前,需要对服务器端发起一次GET请求,协商当前浏览器保存的缓存是否已经过过期,可以已通过给定的“if-modified-since”来判断请求资源是否发生改变。
基于Etag的协商缓存
服务器为资源生成哈希字符窜,只要资源发生改变,那么字符串就会发生变化,这是要实现了判断资源是否发生了改变。
Etag分成强验证和弱验证,强验证保证每一个字符都相同。弱验证是部分资源相同,我们需要根据具体的资源使用场景来进行选择。
假设有一个HTML文件,那么HTML文件应该是协商缓存,可以及时更新,对于图片来说,用强制缓存并且过期时间不宜过长,在面对style.css,可以在.css文件上加上一个版本号。针对大型的应用,可以拆分源码,分包加载。预估资源的缓存时效,控制中间代理的缓存(保证安全性),避免网址的冗余,规划缓存的层次结构。
数据链解决的是三个问题
封装成帧
透明传输
差错控制
其中封装成帧就是将运输层的ip数据报给装入帧里面。具体操作就是在ip数据报的前后分别添加首部和尾部。
针对透明传输的问题,发送端会在数据链路层中数据中出现“soh”,“eot”的前面插入一个转义字符,‘esc’。